Welcome !!
一. 概述
1.1 信息, 数据, 数据处理与管理
1.1.1 数据与信息

1.4 数据库的三级模式

1.4.1 数据独立性
外/模模式 数据与程序之间的逻辑独立性
模内转换 数据的物理独立性
1.6 DBMS

1.7 数据模型
- 数据结构
- 数据操作
- 数据完整性约束
1.8 三个世界
- 实体: 一本书
- 属性
- 实体型: 学生(学号, 姓名, 年龄, 性别, 系)
- 实体集: 所有学生
- 码(key): 学号
- 域: 学号的域为6位整数
- 联系
| 现实世界 | 信息世界 | 计算机世界 |
|---|---|---|
| 事物总体 | 实体集 | 文件 |
| 事件个体 | 实体 | 记录 |
| 特征 | 属性 | 字段 |
| 事物之间的联系 | 实体模型 | 数据模型 |
1.9 数据模型
1.9.1 层次模型
优点: 结构简单, 层次明了
缺点: 不宜直接表达多对多的联系; 插入和删除限制太多;
1.9.2 网状模型
优点: 可实现实体之间的多种复杂性关系; 良好的性能和存储效率
缺点: 由于关系复杂, 不易被用户, 终端掌握
1.9.3 关系模型
数据结构
- 关系与关系实例: 一张表就是一个关系是实例
- 元组: 表的一行
- 属性: 每一列, 由名称, 类型, 长度构成
- 域: 属性的取值范围
- 分量: 单个格的值
- 候选码: 可以唯一标识一个关系的元组, 可以为多个, 全部都是称之为全码
- 主码: 候选码中选一个为主码
- 关系模式: 是对关系的描述, 关系名(属性1, 属性2,)
- 关系实例: 相当于二维表的数据
数据操纵和完整性约束
插入, 删除, 修改, 约束条件
优缺点
优点: 结构简单, 不仅能描述实体, 还能描述实体间的联系, 结果还是操纵结果关系, 更高的数据独立性, 安全保密性
缺点: 查询效率不如非关系模型, 增加DBMC开发的负担; 结构和关系相分离
1.9.4面对对象模型
- 对象和对象标识
- 类和继承
优点: 属性和方法的统一体, 比关系模型更加全,
二. 关系数据库
2.1 关系模型的数据结构及其形式化定义
2.1.1 笛卡尔积
D1 = {李立, 王平, 李伟};
D2 = {男,女};
D1 * D2 = 每个相乘 2*3 = 6行, D1, D2为列属性
2.1.2 关系模式
关系模型是型, 不变, 关系是值, 变
2.2 关系的完整性
主码可以为多个属性组合为一个
非主属性 不包含在主码中的属性称为非主属性。
非主属性是相对与主属性来定义的。
例如:在关系——学生(学号,姓名,年龄,性别,班级)中,主码是“学号”,那么其他的“姓名”、“年龄”、“性别”、“班级”就都可以称为非主属性
- 实体完整性
- 参照完整性(学生表和系别表, 学生表的外码取值, 必须在系别表中找到)
- 用户自定义完整性
2.3 关系代数
2.3.1 传统集合运算
- 并: 两个表的元组合并, 删去重复的元组
- 差: R - S 从R中删除R, S表中相同的元组
- 交: 既属于R, 又属于S的元组
- 笛卡尔积 R中的每一个元组*S的每一个元组
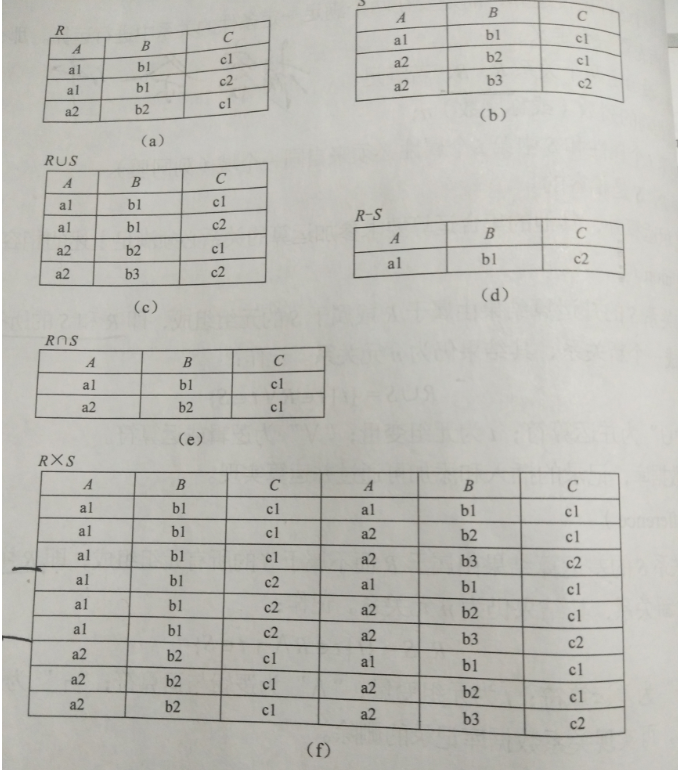
2.3.2 专门的集合运算
- 选取:
- 投影: select id, name from student (id + name)列, 相同的元组去掉
- 除法:

- 连接:自然连接是等值连接去掉重复列; 大于连接: C中的某个值大于D中的值, 就组合成一条元组

三. 关系数据库标准语言
3.1 数据库的创建与使用
3.1.1数据库建立
select database Teach
on
( name = Teach_Data,
filename = 'D:\TeachData.mdf',
size = 10,
maxsize = 500,
filegrowth = 10
)
log on
(
name = Teach_Log,
filename = 'D:\TeachData.ldf',
size = 10,
maxsize = 500,
filegrowth = 10
)3.1.2修改数据库
--增容方式一次增加20MB
alter database Teach
modify file
(
name = Teach_Data,
filegrowth = 20
)
--添加文件
alter database Teach
add file
(
name = Teach_DataNew,
filename = 'E:\Teach_DataNew',
size = 100,
maxsize = 200,
filegrowth = 10
)
-- 删除次要文件
alter Database Teach
remove file Teach_DataNew3.1.3 删除数据库
drop database Teach3.1.4 数据类型
- char : 定长的非Unicode字符
- varchar : 非定长的非Unicode字符,(即ASCII码)
- nchar : Unicode字符, 定长
- nvarchar : Unicode, 非定长
- datetime : 日期时间型
- money: 货币型
3.4 数据表的创建与使用
3.4.1 数据表的创建
create table S
(
SNO varchar(6),
SN nvarchar(10),
Sex nchar(1) default '男',
Age int,
Dept nvarchar(20)
)3.4.2 数据表的约束
(1) 非空约束
SNO varchar(6) not null,
(2) 唯一约束
SN nvarchar(10) constraint name_uniq unique,
复合约束
create table S
(
SNO varchar(6),
SN nvarchar(10),
Sex nchar(1) default '男',
Age int,
Dept nvarchar(20),
constraint name_uniq unique(SN, Sex)
)
(3) 主键约束
SNO varchar(6) constraint name_prim primary key,
复合主键
create table S
(
SNO varchar(6),
SN nvarchar(10),
Sex nchar(1) default '男',
Age int,
Dept nvarchar(20),
constraint name_prim primary key(SN, Sex) ##一般复合都放在最后一行
)
(4) 外键
create table S
(
SNO varchar(6) not null constraint name_fore foreign key references S(SNO), ##非空和外键约束之间没有,
SN nvarchar(10),
Sex nchar(1) default '男',
Age int,
Dept nvarchar(20)
)
(5) check
create table S
(
SNO varchar(6),
SN nvarchar(10),
Sex nchar(1) default '男',
Age int,
Score numeric(4,1) constraint Score_link check(Score >= 0 and Score <= 100)## numeric(4,1) 总位数4位, 小数点后1位, 整数部分3位, 不是&&, 是and, 也可以用between and
)数据表增, 删
##增
alter table S
add
Class_No varcher(6),
Address nvarchar(20)
constraint Score check(Score between 0 and 100) ##增加可以增加约束, 不止表
##删
drop table S
3.5 单关系表的查询
3.5.1 常用运算符
| ALL | 用于将一个值同另一个值集中所有的值进行比较。 |
|---|---|
| AND | 使得在 WHERE 子句中可以同时存在多个条件。 |
| ANY | 用于将一个值同条件所指定的“列表中的任意值相比较。 |
| BETWEEN | 给定最小值和最大值,BETWEEN 运算符可以用于搜索区间内的值。 |
| EXISTS | 用于在表中搜索符合特定条件的行。 |
| IN | 用于将某个值同指定的一列字面值相比较。 |
| LIKE | 用于使用通配符对某个值和与其相似的值做出比较。 |
| NOT | NOT 操作符反转它所作用的操作符的意义。例如,NOT EXISTS、NOT BETWEEN、NOT IN 等。这是一个求反运算符。 |
| OR | OR 运算符用于在 SQL 语句中连接多个条件。 |
| IS NULL | NULL Operator 用于将某个值同 NULL 作比较。 |
| UNIQUE | UNIQUE 运算符检查指定表的所有行,以确定没有重复。 |
| <> | 不等于 同!= |
注: in、exists、all、any用法与区别
any表示有任何一个满足就返回true,all表示全部都满足才返回true。
=any 与子查询in相同
<>any 与not in相同
参考:[SQL 中的in、exists、all、any用法与区别]http://www.freeoa.net/osuport/db/sql-in-exists-all-any-some_3280.html
3.5.2 通配符
| % | 代表0个或多个字符 | ‘ab%’, ‘ab’后可接任意字符 |
|---|---|---|
| _ | 代表一个字符 | ‘a_b’, ‘a’和‘b’之间可以有一个字符 |
| [] | 在某一范围的字符 | [0 |
| [^] | 不在某一范围 | [^0-9] 不在0~9之间 |
3.5.3 库函数
| AVG |
|---|
| SUM |
| MAX |
| MIN |
| COUNT |
select SUM(Sore) as TotalScore, AVG(Score) as AvgScore
from SC
where (SNO = 'S1')3.5.4分组查询
selet SNO, COUNT(*) as SC_Num
from SC
group by SNO
having (count(*) >= 2)
order by Score DESC // 降序
order by Score ASC // 升序3.6 多表查询
##可以将查询出的表 as 命名为一个新的表 将查出来的表进行命名为一个新的表, 和之前的表进行连接
select Temp1.SNO, Student.SNAME, Temp1.GRADE
from Student inner join(select SNO, GRADE
from Sc
where CNO = '1') as Temp1 on Temp1.SNO = Student.SNO
order by GRADE desc
##善于用 not exists 来查询
#存储查询结果到表上
select SNO as 学号
into Cal_Table
from SC
group by SNO3.7 修改数据表中的数据
##更新
update T
set dept = '信息',
where TN = '刘伟'
##删除
delete
from T
where TN = '李伟'
3.8 视图
理解:
- 视图<==>一条查询sql语句,用于显示一个或多个表或其他视图中的相关数据。
- 视图将一个查询的结果作为一个表来使用,因此视图可以被看作是存储的查询或一个虚拟表,
- 与真实表不同,视图不会要求分配存储空间,视图中也不会包含实际的数据。
- 视图只是定义了一个查询,视图中的数据是从基表中获取,这些数据在视图被引用时动态的生成。由于视图基于数据库中的其他对象,因此一个视图只需要占用数据字典 中保存其定义的空间,而无需额外的存储空间,并且基表的变化会导致视图相应的改变
- 可以作为一个安全机制, 通过视图, 可以不给用户其他重要的信息
- 可以定制用户数据,聚焦特定的数据
- 可以简化数据操作。
- 基表中的数据就有了一定的安全性
- 可以合并分离的数据,创建分区视图
- 视图定义后, 对视图的查询如同对基本表查询一样
3.8.1 创建, 修改, 删, 查视图
## 创建
create view S_SC_C(SNO, SN, CN,Score) ##返回的表的列名
as select SNO, SN, CN, Score ##x和上面的一致
from S, C, SC
group by SNO
## 删除
drop view <视图名>
## 修改
alter view S_SC_C(SNO, SN, CN,Score)
as select SNO, SN, CN, Score ##x和上面的一致
from S, C, SC
group by SNO
## 查询
select TNO, TN
from Sub_T
where Prof = '教授'
## 更新
## 添加(insert)
insert into Sub_T(TNO, TN, Prof)
values('T6', '李丹','Milk') ##系统在执行此句时, 首先从数据字典中找到Sub_T的定义, 然后将此定义和添加操作结合起来, 转换成等价的对基本表T的添加
## 更新(update)
update Sub_T
set Prof = '副教授'
where (TN = '刘伟')
## 删除(dalete)
delete from Sub_T
where TN = '刘伟'3.9 索引
理解: 就像<新华词典>的偏旁部首, 书籍的目录
-
汉语字典的正文本身就是一个聚集索引。比如,我们要查”安”字,就会很自然地翻开字典的前几页,因为”安”的拼音是”an”,而按照拼音排序汉字的字典是以英文字母”a”开头并以”z”结尾的,那么”安”字就自然地排在字典的前部。如果您翻完了所有以”a”开头的部分仍然找不到这个字,那么就说明您的字典中没有这个字;同样的,如果查”张”字,那您也会将您的字典翻到最后部分,因为”张”的拼音是”zhang”。也就是说,字典的正文部分本身就是一个目录,您不需要再去查其他目录来找到您需要找的内容。 我们把这种正文内容本身就是一种按照一定规则排列的目录称为”聚集索引”。 避免了每次都查询全局数据
如果您认识某个字,您可以快速地从自动中查到这个字。但您也可能会遇到您不认识的字,不知道它的发音,这时候,您就不能按照刚才的方法找到您要查的字,而需要去根据”偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。但您结合”部首目录”和”检字表”而查到的字的排序并不是真正的正文的排序方法,比如您查”张”字,我们可以看到在查部首之后的检字表中”张”的页码是672页,检字表中”张”的上面是”驰”字,但页码却是63页,”张”的下面是”弩”字,页面是390页。很显然,这些字并不是真正的分别位于”张”字的上下方,现在您看到的连续的”驰、张、弩”三字实际上就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。 我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为”非聚集索引”。
唯一索引
如果确定某个数据列只包含彼此各不相同的值,在为这个数据列创建索引的时候,就应该用关键字UNIQUE把它定义为一个唯一索引,Mysql会在有新纪录插入数据表时,自动检查新纪录的这个字段的值是否已经在某个记录的这个字段里出现过了。如果是,将拒绝插入那条新纪录。也就是说,唯一索引可以保证数据记录的唯一性。事实上,在许多场合,人们创建唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复.
视图索引
全文索引 : 定义一个词库, 查找存储每个词条出现的频率和位置
XML索引
3.9.1 创建, 修改, 删除, 查看索引
//创建索引
create [unique] [clustered] [nonclustered] index index_name
on table_or_view_name (column_name [ASC | DESC])
create unique index SCI on SC(SNO, CNO)
//先按SNO的递增顺序索引, 对于相同的SNO, 又按CNO的递增顺序索引
//修改索引
alter index {index | all}
on table_or_view_name
//查看索引
exec Sp_helpindex SC3.10 小结
| 数据定义 | create , drop , alter |
|---|---|
| 数据查询 | select |
| 数据操纵 | insert , update delete |
| 数据控制 | grant, revoke |
四. 关系数据理论
4.1 规范化理论
- 理论为什么会产生?
如何设计一个适合的关系型数据库, 其关键是设计关系型数据库的模式, 包括: 数据库应包含多少个关系模式, 每一个关系模式应包括哪些属性以及如何如何将这些相互关联的模式组建成一个完整的关系型数据库, 这牵扯到数据库的运行效率, 设计的成败.
因此, 需要从关系数据库理论出发, 在理论指导下进行工作, 主要包含三方面: 函数依赖, 范式, 模式设计.
没有理论指导下设计表出现的问题–反例
```sql
- 数据冗余
- 插入异常(两个主码相关联, 不能单独向一个主码插入数据)
- 删除异常(会附带删除其他关键信息)
更新异常(会造成数据不一致)
关系包罗万象, 出现这样的问题在于: **属性之间存在相互关联**
4.2 函数依赖(语义的范畴, 根据现实来看)
- 各属性之间的相互依赖, 相互制约.
- 一般分为函数依赖(重要)和多值依赖
例子: 由于一个SNO只对应一个学生, 而一个学生只能属于一个系, 因此当sno确定后, 该学生的SN, Age, Dept的值, 也随之唯一地确定了, 这个类似于单值函数与变量之间的关系, 设函数$y = f(x)$ ,当自变量$x$确定, , $y$也随之确定, 我们可以说: SNO可以唯一确定函数(SN, Age, Dept)的值, 或者说(SN, Age, Dept)函数依赖于SNO, 即$函数X\to Y(X决定Y, Y依赖于X)$ 还有$X\longleftrightarrow Y(相互依赖)$
说明:
- $Y\subseteq X, 一定存在X\to Y$
- 当$ X 与 Y 有 1:1 $联系时, $X\longleftrightarrow Y$
- 当$X与Y有m: 1$联系时, 只有$X\to Y$
- 当$X与Y有m: n$联系时, 不存在任何函数依赖
4.2.1 函数依赖的逻辑蕴含定义
$设f是在关系R(U)上成立的集合, X , Y是属于U的子集,$ $ X\to Y是一个函数依赖, 如果能从F中导出X\to Y, $即$R中每一个F的关系r也满足X\to Y, 称X\to Y为F的逻辑蕴含(或F逻辑蕴含X\to Y),记为F\mid =X\to Y$
F是函数依赖集, 被函数F逻辑蕴含的全部函数依赖集合, 称为函数依赖F的闭包, 即$F^{+} $
$F^{+} $中的函数依赖都是能从F中推出来的
例: 结合图来理解上面的句子
4.2.2 推理规则
- 自反律 $Y\subseteq X\subseteq U, 则X\to Y在R上成立$
- 增广律 $X\to Y$在R上成立 $Z\subseteq U$ 则$ZX \subseteq ZY$
- 传递律
- 合并律: $X\to Y , X\to Z, 则X\to YZ$
- 伪传递律: $X\to Y, YW\to Z$在R上成立, 则$XW\to Z$上成立
- 分解律: $X\to Y, Z\subseteq Y$, 在R上成立, 则$X\to Z$
- 复合律: $X\to Y, W\to Z, 则XW\to YZ$
4.2.3 完全函数依赖与部分函数依赖
完全函数依赖: X和Y是U的子集, 如果$X\to Y$, 并且对于X的任意一个真子集$X{‘}$, 都有$X{‘}\nrightarrow Y$, 则成Y对X完全依赖, 如果有则为部份依赖,
例: $SNO\nrightarrow Score $ && $CNO\nrightarrow Score$, 则 $(SNO, CNO)\stackrel{f}{\longrightarrow}Score$
4.2.4 传递依赖与直接依赖
$X, Y, Z$是U的子集, 若$X\to Y$, 但$Y\nrightarrow X$, 且$Y \to Z$, 则成$Z对X传递函数依赖$, 假如$Y\to X$, 则$X\leftrightarrow Y$称Z对X 直接函数依赖.
就像A//B, B//C, 则A// C
4.2.5 属性集闭包
由来:
在实际工作中,人们往往需要知道某个函数依 赖$X\to Y$是否成立,如果已经计算出$F^{+}$,只要检查该函数依赖是否在$F^{+}$中就能得到准确的结果。*问题是计算$F^{+}$是一个相当复杂且困难的问题,且在$F^{+}$中有许多冗余的信息。为了能够尽快确定函数依赖$X\to Y$是否成立,人把计算$F^{+}$简化为计算属性集的闭包$X^{+}$,即若要判断某个函数依赖是否在$F ^{+}$ 中,只要找到那些所有由X决定的属性集,即X的属性集的闭包$X^{+}$就能确定答案。**(结合上面的图理解)
也就是求$F^{+}$太麻烦, 转而求$ X^{+} $
例: 
4.2.6 候选码的求解
函数依赖是码的概念的推广
什么是候选码?
如果X的任一真子集$X^{‘}$ 都有$X^{‘} \to U$, 不成立, 称$X是R上的候选码$
怎么求?
对于给定的关系R(A1,A2,…, An)和函数依赖集F,可将其属性分为四类
L类:仅出现在F的函数依赖左部的属性;
R类:仅出现在F的函数依赖右部的属性;
N类:在F的函数依赖左右两边均未出现的属性;
LR类:在F的函数依赖左右两边均出现的属性。
- 若X是L类, X必为R中的任一候选码成员, 假如$X^{+}$ 包含了R的全部属性, 则X是R的唯一候选码
- 若X是R类, X不在任一候选码中
- 若X是N类, X必为R中的任一候选码成员
- 若X是LR类, X可能是, 也可能不是任一候选码
- 若X是L和N类的属性集, 且$X^{+}$包含了R的全部属性
例:

4.3 关系模式的范式
消除关系模式中的数据冗余, 消除数据依赖中不合适的部分.
按照不同的规范化要求分为5个等级$5NF\subseteq 4NF\subseteq 3NF\subseteq 2NF\subseteq 1NF$
1NF : 关系中的属性都不可再分
2NF : 满足1NF, 每个非主属性完全依赖于R的主码, R的主码为1个 or R全体属性为主属性
分解原则: “一事一地”,让一个关系只描述一个实体或者实体间的联系
例子:
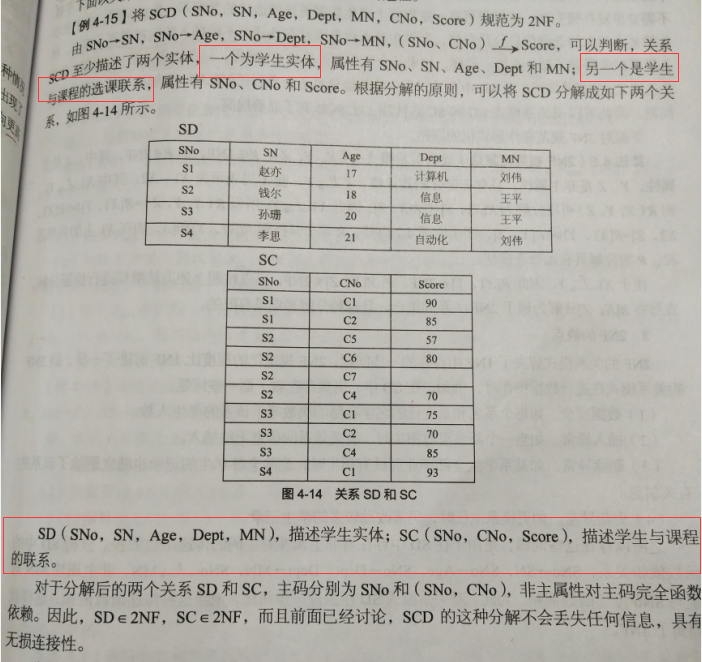
缺点: 数据冗余, 插入异常, 删除异常, 更新异常
原因: 非主属性对主码有传递依赖性
3NF: 属于2NF, 非主属性都不传递依赖于R的主码
算法:

缺点: 没有限制主属性对主码的依赖, 可能仍有冗余
BCNF : 消除任何属性对主码的依赖
$R\subseteq BCNF$, 则, $R\subseteq 3NF$, 反之不成立
算法: 待补充
五. 数据库安全保护
六. 数据库设计
6.1 数据库设计方法
- 基于E-R模型
- 基于3NF
- 基于视图
6.2 数据库设计流程
系统需求分析阶段
基础, 收集数据库所有用户的信息内容和处理要求, 并加以规范化和分析
调查分析用户的活动
收集和分析需求数据, 确定系统边界
概念结构
把用户的信息统一到一个整体逻辑结构中, 能表达用户的要求, 独立于任何DBMS软件和硬件的概念模型
逻辑结构
将上一步所得到的概念模型转换为某一个DBMS所支持的数据模型, 并对其优化
物理结构
建立一个完整的能实现的数据结构, 包括存储结构和存取方法
数据库实施
将原始数据装入数据库, 建立一个具体的数据库并编写和调试
数据库运行与维护
收集和记录实际系统运行的数据
七. 高级应用
7.1.1 变量
全局变量: @@
局部变量: declare @变量名 = 变量值 //set @变量名 = 变量值
例: declare @id char(8), @sn varchar(10)
select @id = '1001 0001'
--------------------------------------
--begin end相当于{}
begin
命令行
end
---------------------------------------
if else
---------------------------------------
例:--go别忘写,
use Teach
go
declare @message varchar(255)
if exists (select * from S where SNO = 'S1')
set @message = '存在学号为S1的学生'
else
set @message = '不存在学号为S1的学生'
print @message
go
---------------------------------------
例: case语句
use teach
go
select SNO,
sex =
case Sex
when '男' then 'M'
when '女' then 'F'
end
from S
go
--------------------------------------
beg: goto beg
declare @s smallint, @i smallint
set @i = 0
set @s = 0
beg:
if(@i <= 10)
begin
set @s = @s + @i
set @i = @i + 1
goto beg
end
print @s
return
------------------------------------
--用户自定义函数
create function Score_Table (@student_id char(6))
return @T_score Table(Cname varcher(20), Grade int) @名称 table (结构)
as
begin
insert into @T_score //相当于定义了一个表, 将查出的表数据复制到
select CN, Score
from SC, C
where SC.CNo = C.CNo
return
end7.1.2 存储过程
为什么?
每次调用一次SQL语句就要进行编译, 执行, 如果多个用户同时进行, SQL效率将会很低下. 因为不知道客户机程序到死要执行什么语句, 每次要进行编译, 然后执行会产生大量流量, 效率低
因此, 存储过程面世, 它是一组完成特定任务的SQL语句, 这些语句编译后存储在数据库中, 用户只需传送参数来调用它
优点:
- 模块化程序设计
- 高效率的执行
- 减少网络流量
- 可作为安全机制
存储过程的分类
1. 系统存储过程
2. 用户自定义过程
3. 扩展存储过程use Teach
go
create procedure QueryTeach
(
@sno varcher(6),
@sn nvarcher(10) output,
@dept nvarcher(20) output
)
as
select @sn = SN, @dept = Dept
from S
where SNo = @sno
--查看
use Teach
go
exec sp_helptext MyProc
--删除
use Teach
go
drop procedure MyNewProc
--执行
use Teach
go
exec MyProc
--修改
alter procedure MyNewProc7.1.3 触发器
7.1.3.1优点: 自动激活
7.1.3.2分类:
DML触发器(insert, update, detele)
- after触发器 执行之后, 才激活执行, 主要用于记录数据变更后的处理或检查, 不可定义视图
- instead of触发器, 先执行触发器中的语句, 再执行语句, 可以定义在视图上
DDL触发器
create , alter , drop
登陆触发器
7.1.3.3工作原理
| 操作 | inserted表 | deleted表 |
|---|---|---|
| 增加insert | 存放增加的记录 | 无 |
| 删除delete | 无 | 存放的删除的数据 |
| 修改update | 存放更新后的数据 | 存放更新之前的数据 |
7.1.3.4 语句
--创建DML触发器
use Teach
go
create trigger del_s on S
after delete
as
delete from SC
where Sc.SNO in (select SNO from deleted)
--创建DDL触发器
use Teach
go
create trigger safety on database
for Drop_table
as print '不能删除'
rollback
go
--查看
use Teach
go
exec sp_helptrigger 'S'
go
--修改
alter trigger name
on
--删除
drop trigger table_name7.2 备份和还原
备份类型
- 数据库完整备份
- 差异备份 : 完整备份的补充, 只备份上一次完整备份后(注意: 不是上一次差异备份后)数据库变动的部分,
- 事务日志备份 : 只备份数据库事务日志的内容
- 文件及文件组备份: 备份单一数据库文件
还原类型
- 简单还原
- 完全还原
- 批日志还原



